seaborn.violinplot(*, x=None, y=None, hue=None, data=None, order=None, hue_order=None, bw='scott', cut=2, scale='area', scale_hue=True, gridsize=100, width=0.8, inner='box', split=False, dodge=True, orient=None, linewidth=None, color=None, palette=None, saturation=0.75, ax=None, **kwargs)¶Draw a combination of boxplot and kernel density estimate.
A violin plot plays a similar role as a box and whisker plot. It shows the distribution of quantitative data across several levels of one (or more) categorical variables such that those distributions can be compared. Unlike a box plot, in which all of the plot components correspond to actual datapoints, the violin plot features a kernel density estimation of the underlying distribution.
This can be an effective and attractive way to show multiple distributions of data at once, but keep in mind that the estimation procedure is influenced by the sample size, and violins for relatively small samples might look misleadingly smooth.
Input data can be passed in a variety of formats, including:
Vectors of data represented as lists, numpy arrays, or pandas Series
objects passed directly to the x, y, and/or hue parameters.
A “long-form” DataFrame, in which case the x, y, and hue
variables will determine how the data are plotted.
A “wide-form” DataFrame, such that each numeric column will be plotted.
An array or list of vectors.
In most cases, it is possible to use numpy or Python objects, but pandas objects are preferable because the associated names will be used to annotate the axes. Additionally, you can use Categorical types for the grouping variables to control the order of plot elements.
This function always treats one of the variables as categorical and draws data at ordinal positions (0, 1, … n) on the relevant axis, even when the data has a numeric or date type.
See the tutorial for more information.
data or vector data, optionalInputs for plotting long-form data. See examples for interpretation.
Dataset for plotting. If x and y are absent, this is
interpreted as wide-form. Otherwise it is expected to be long-form.
Order to plot the categorical levels in, otherwise the levels are inferred from the data objects.
Either the name of a reference rule or the scale factor to use when computing the kernel bandwidth. The actual kernel size will be determined by multiplying the scale factor by the standard deviation of the data within each bin.
Distance, in units of bandwidth size, to extend the density past the
extreme datapoints. Set to 0 to limit the violin range within the range
of the observed data (i.e., to have the same effect as trim=True in
ggplot.
The method used to scale the width of each violin. If area, each
violin will have the same area. If count, the width of the violins
will be scaled by the number of observations in that bin. If width,
each violin will have the same width.
When nesting violins using a hue variable, this parameter
determines whether the scaling is computed within each level of the
major grouping variable (scale_hue=True) or across all the violins
on the plot (scale_hue=False).
Number of points in the discrete grid used to compute the kernel density estimate.
Width of a full element when not using hue nesting, or width of all the elements for one level of the major grouping variable.
Representation of the datapoints in the violin interior. If box,
draw a miniature boxplot. If quartiles, draw the quartiles of the
distribution. If point or stick, show each underlying
datapoint. Using None will draw unadorned violins.
When using hue nesting with a variable that takes two levels, setting
split to True will draw half of a violin for each level. This can
make it easier to directly compare the distributions.
When hue nesting is used, whether elements should be shifted along the categorical axis.
Orientation of the plot (vertical or horizontal). This is usually
inferred based on the type of the input variables, but it can be used
to resolve ambiguity when both x and y are numeric or when
plotting wide-form data.
Width of the gray lines that frame the plot elements.
Color for all of the elements, or seed for a gradient palette.
Colors to use for the different levels of the hue variable. Should
be something that can be interpreted by color_palette(), or a
dictionary mapping hue levels to matplotlib colors.
Proportion of the original saturation to draw colors at. Large patches
often look better with slightly desaturated colors, but set this to
1 if you want the plot colors to perfectly match the input color
spec.
Axes object to draw the plot onto, otherwise uses the current Axes.
Returns the Axes object with the plot drawn onto it.
See also
boxplotA traditional box-and-whisker plot with a similar API.
stripplotA scatterplot where one variable is categorical. Can be used in conjunction with other plots to show each observation.
swarmplotA categorical scatterplot where the points do not overlap. Can be used with other plots to show each observation.
catplotCombine a categorical plot with a FacetGrid.
Examples
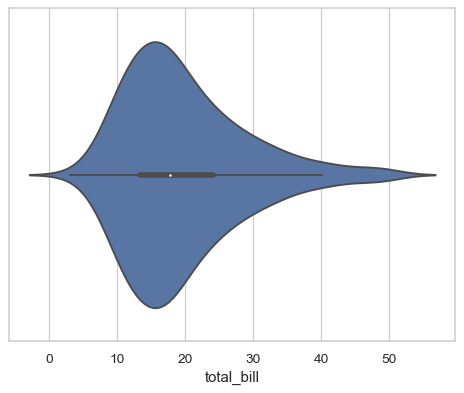
Draw a single horizontal violinplot:
>>> import seaborn as sns
>>> sns.set_theme(style="whitegrid")
>>> tips = sns.load_dataset("tips")
>>> ax = sns.violinplot(x=tips["total_bill"])
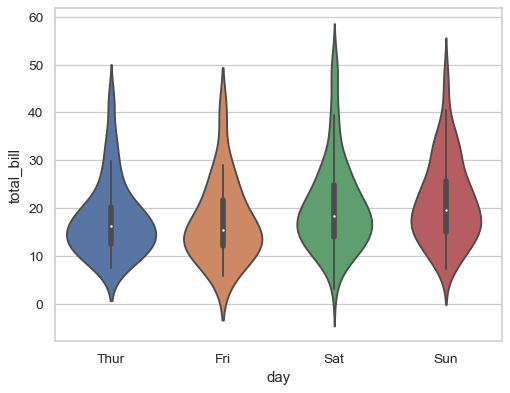
Draw a vertical violinplot grouped by a categorical variable:
>>> ax = sns.violinplot(x="day", y="total_bill", data=tips)
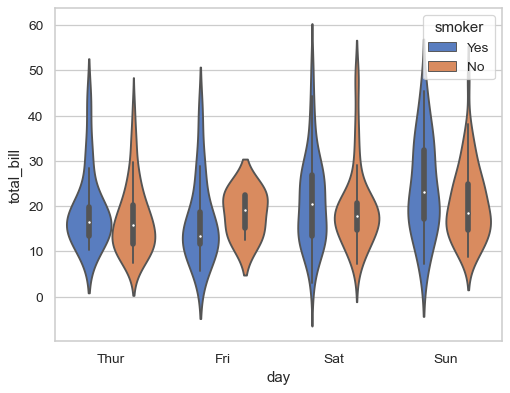
Draw a violinplot with nested grouping by two categorical variables:
>>> ax = sns.violinplot(x="day", y="total_bill", hue="smoker",
... data=tips, palette="muted")
Draw split violins to compare the across the hue variable:
>>> ax = sns.violinplot(x="day", y="total_bill", hue="smoker",
... data=tips, palette="muted", split=True)
Control violin order by passing an explicit order:
>>> ax = sns.violinplot(x="time", y="tip", data=tips,
... order=["Dinner", "Lunch"])
Scale the violin width by the number of observations in each bin:
>>> ax = sns.violinplot(x="day", y="total_bill", hue="sex",
... data=tips, palette="Set2", split=True,
... scale="count")
Draw the quartiles as horizontal lines instead of a mini-box:
>>> ax = sns.violinplot(x="day", y="total_bill", hue="sex",
... data=tips, palette="Set2", split=True,
... scale="count", inner="quartile")
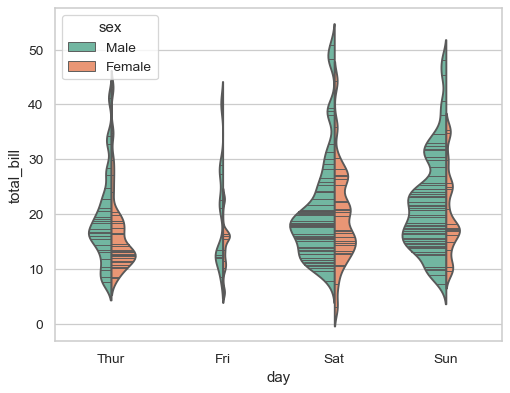
Show each observation with a stick inside the violin:
>>> ax = sns.violinplot(x="day", y="total_bill", hue="sex",
... data=tips, palette="Set2", split=True,
... scale="count", inner="stick")
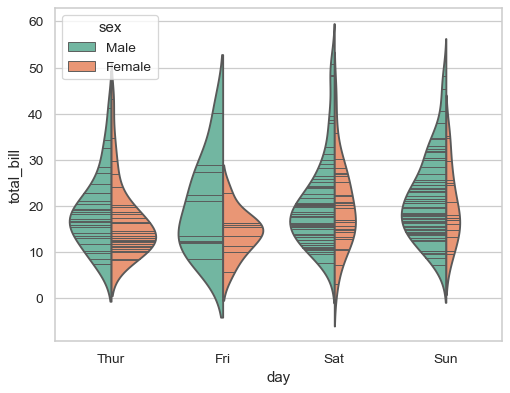
Scale the density relative to the counts across all bins:
>>> ax = sns.violinplot(x="day", y="total_bill", hue="sex",
... data=tips, palette="Set2", split=True,
... scale="count", inner="stick", scale_hue=False)
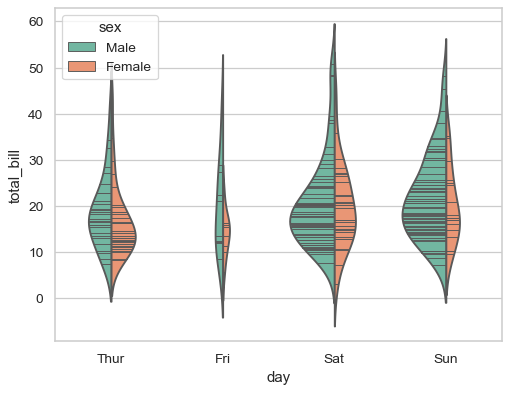
Use a narrow bandwidth to reduce the amount of smoothing:
>>> ax = sns.violinplot(x="day", y="total_bill", hue="sex",
... data=tips, palette="Set2", split=True,
... scale="count", inner="stick",
... scale_hue=False, bw=.2)
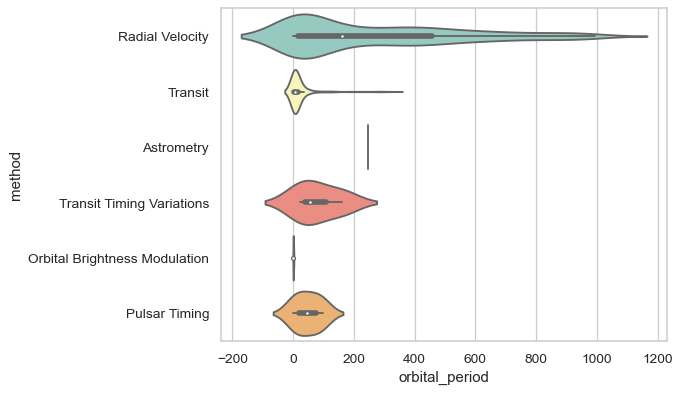
Draw horizontal violins:
>>> planets = sns.load_dataset("planets")
>>> ax = sns.violinplot(x="orbital_period", y="method",
... data=planets[planets.orbital_period < 1000],
... scale="width", palette="Set3")
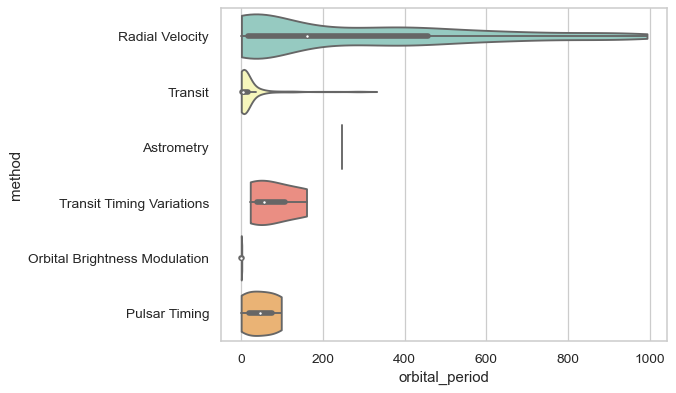
Don’t let density extend past extreme values in the data:
>>> ax = sns.violinplot(x="orbital_period", y="method",
... data=planets[planets.orbital_period < 1000],
... cut=0, scale="width", palette="Set3")
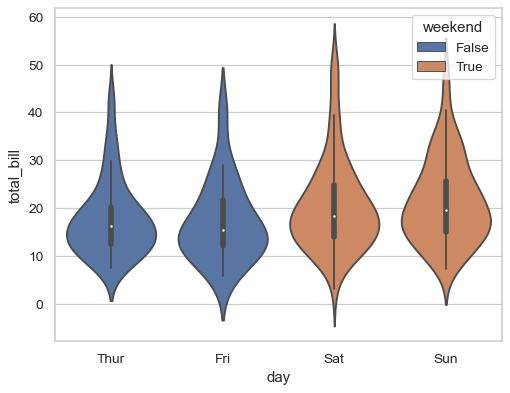
Use hue without changing violin position or width:
>>> tips["weekend"] = tips["day"].isin(["Sat", "Sun"])
>>> ax = sns.violinplot(x="day", y="total_bill", hue="weekend",
... data=tips, dodge=False)
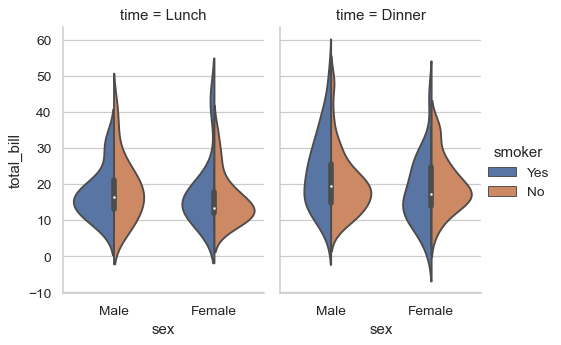
Use catplot() to combine a violinplot() and a
FacetGrid. This allows grouping within additional categorical
variables. Using catplot() is safer than using FacetGrid
directly, as it ensures synchronization of variable order across facets:
>>> g = sns.catplot(x="sex", y="total_bill",
... hue="smoker", col="time",
... data=tips, kind="violin", split=True,
... height=4, aspect=.7);